
心理所合作研究揭示抑郁症污名信息在社交媒体环境下的心理语言表达模式
抑郁症是一种严重的心理疾病,根据世界卫生组织(WHO)的数据显示,2015年,全球约有4.4%的人口受到抑郁症的困扰。接受专业的心理健康援助是降低抑郁症危害的有效措施。但是,现实社会中存在着抑郁症污名现象,这一现象会在抑郁症患者身上加诸耻辱性标签,引发他人对患者的歧视、排斥,从而导致抑郁症患者因羞于主动寻求心理健康援助而错失最佳心理干预时期。减少抑郁症污名现象将有利于改善抑郁症患者的心理健康水平。
大众媒体(电视、报纸、广播等)是信息传播的重要渠道。理解抑郁症污名信息的特征,有利于从海量的大众媒体信息中识别、研究抑郁症污名信息,从而为制定相应的干预策略提供有益的帮助。近年来,伴随着互联网的发展,社交媒体(如Twitter、新浪微博)已经逐渐成为一种新型的大众媒体。与传统的大众媒体相比较,新媒体环境下的信息内容与沟通方式均发生了巨大的变化。但是,新媒体环境下的抑郁症污名信息的特征至今尚不明确。
基于上述背景,中国科学院行为科学重点实验室朱廷劭研究组联合北京林业大学李昂组开展研究,旨在探索抑郁症污名信息在社交媒体环境下的心理语言表达模式。
该研究以新浪微博为研究平台,利用应用程序接口(API)下载了超过一百万名活跃用户公开发表的微博,并从中筛选出15879条带有抑郁症关键词的微博,形成一个子数据集。在此基础上,一方面,利用人工编码方法,分析子数据集中每条微博的内容是否反映了抑郁症污名,以及具体反映了哪种类型的抑郁症污名,将编码结果作为因变量;另一方面,利用心理语言分析方法,通过简体中文版LIWC程序,从每条微博的内容中提取66类心理语言特征,将特征取值作为自变量。随后,利用机器学习方法(Logistic回归、神经网络、支持向量机、随机森林),分别建立两种不同用途的分类预测模型:(1)旨在区分污名与非污名微博的分类预测模型、(2)旨在区分不同类型的污名微博的分类预测模型。
研究结果显示,在15879条微博中,6.09%的微博被确认为抑郁症污名信息。其中,最常见的三种污名类型是:(1)认为抑郁症患者的言行举止难以预料(不可预知污名)、(2)认为罹患抑郁症是个性软弱的表现(软弱污名)、(3)认为抑郁症不是一种医学疾病(诈病污名)。分类预测模型的训练结果显示(见图1),区分污名与非污名微博的精确度可以达到75.2%(F-Meaure);区分最常见的三种类型的污名微博的精确度可以达到86.2%(F-Measure)。微博用户在发布抑郁症污名信息时,会更多使用一些特定类别的词汇,包括:差距词、排除词、消极情绪词、社会历程词、暂定词。
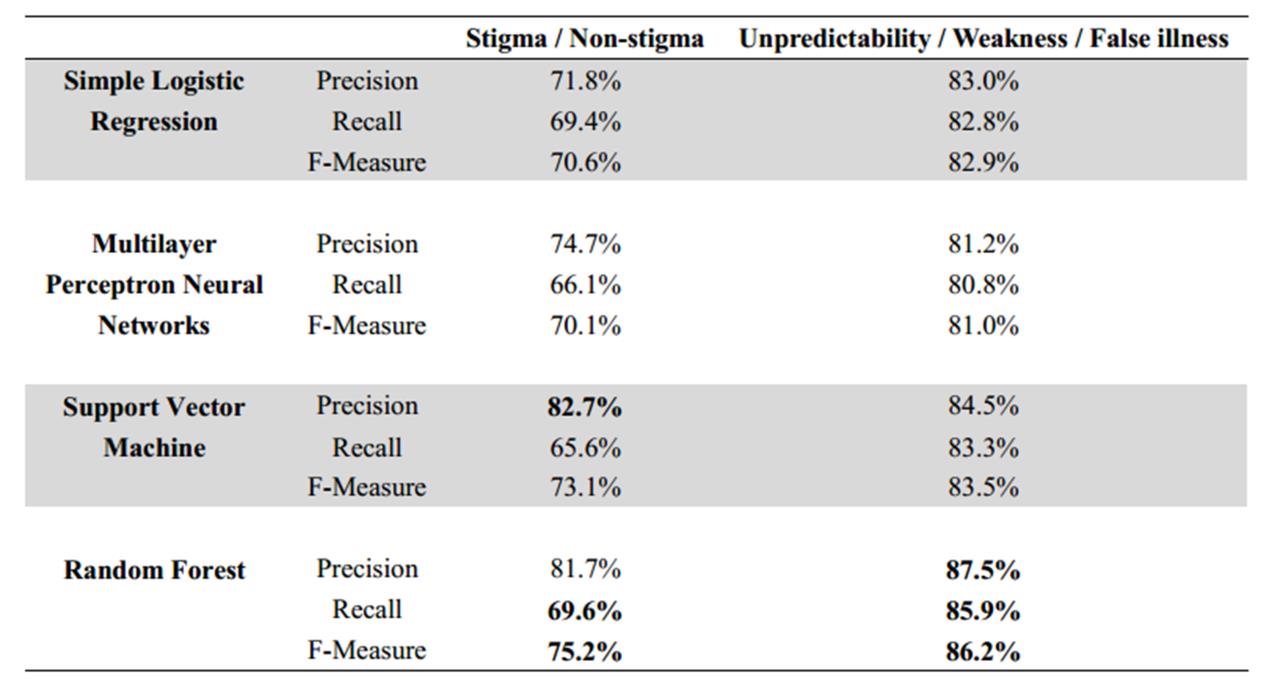
图1 分类预测模型的训练结果
该研究发现了抑郁症污名信息在社交媒体环境下的心理语言表达模式,证明利用心理语言分析方法有助于实现抑郁症污名信息的在线识别。利用建立好的分类预测模型,可以在社交媒体环境下对海量用户信息开展实时、自动监测,提高对抑郁症污名信息的识别效率。
该研究受国家重点基础研究发展计划(2014CB744600)的课题资助。相关研究成果在线发表于国际学术期刊Journal of Affective Disorders:
Li, Ang., Jiao, Dongdong., Zhu, Tingshao. (2018). Detecting depression stigma on social media: A linguistic analysis. Journal of Affective Disorders. DOI: https://doi.org/10.1016/j.jad.2018.02.087
附件下载: