
Psychological Review:心理所构建中文阅读的认知计算模型
中文是中华民族的宝贵财富,是全球近四分之一人口的母语,更是凝聚全球华人的重要纽带。对中文阅读的认知机理进行研究,并使其更好地为中文阅读者服务,具有重要的理论与实际意义。与英文等拼音文字相比,中文具有很多鲜明的特点。其中一个显著特点是中文文本在词和词之间没有空格,这使得现有的阅读模型面对中文时都无能为力。以大量实验研究为基础,中国科学院行为科学重点实验室李兴珊研究员构建了中文阅读过程中认知加工的计算模型(中文阅读模型,简称CRM),成果发表在《Psychological Review》上。
为较全面地研究中文阅读机制,CRM整合了中文阅读过程中的词汇加工和眼动控制两大模块。词汇加工模块使用交互激活框架来模拟词汇加工过程;眼动控制模块则利用词汇加工模块提供的字词激活信息来决定眼睛移动时间和位置。
由于中文文本中没有词间空格,CRM对中文阅读中的词切分问题提出了一系列原创性的假设:即词汇加工模块在注视点周围的阅读知觉广度范围内获取新信息,从而激活知觉广度范围内的汉字可以组成的全部词汇,并相互竞争;当一个词在竞争中胜出后,该词即被识别同时完成了词切分。基于这些假设,CRM可以将句子中的连续汉字切分成词,并在句子阅读中进行识别。
针对眼动控制,CRM采用研究团队提出的基于加工的眼动落点选择策略:在一个注视点,读者尽可能多地加工可以看到的字,然后下一次眼跳落在已经识别的字的后面。这样该模型很好地解释了词汇识别与眼动控制的关系。
CRM成功地模拟了以往研究中所揭示的关于中文阅读中词汇加工和眼动控制之间关系的主要发现,并解释了中文读者如何进行眼跳目标的选择、如何切分歧义字段、以及如何利用副中央凹视觉区进行信息加工等问题。
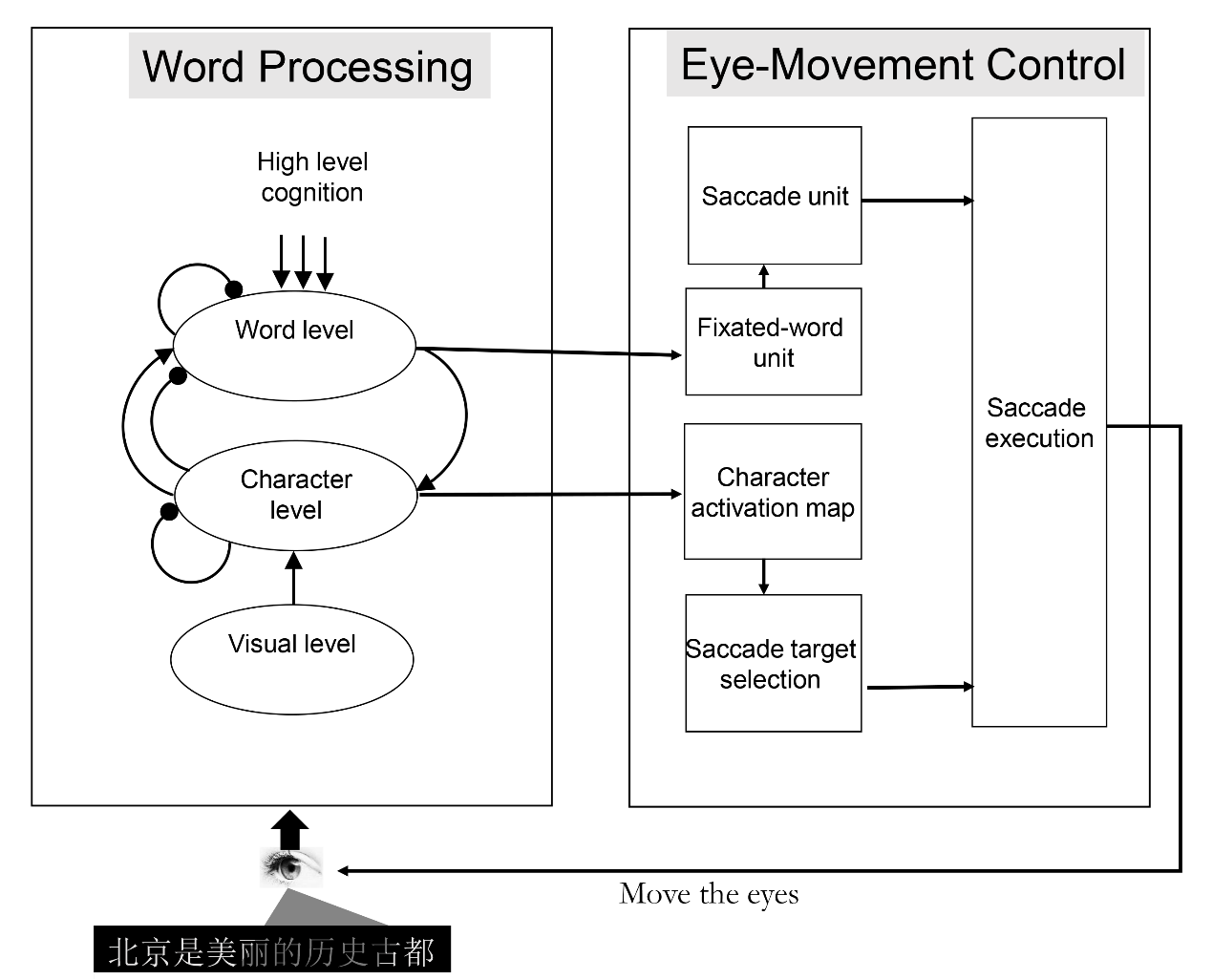
CRM解决了中文词在缺乏词间空格的情况下如何实现识别和切分以及如何控制眼动的难题,对揭示中文阅读加工的独特性与人类阅读加工的一般性具有重要意义。研究中文阅读的独特性有助于回答现有的拼音文字阅读模型无法回答的问题,比如CRM重点关注的“中文读者如何确定词边界”的问题在拼音文字阅读中并不存在。关于此问题的研究也已经开始定义和塑造一些有关人类书面语言理解的关键问题。此外,CRM的建立也为解决自然语言处理领域中的中文分词等关键问题提供了科学依据。
上述建模工作是在李兴珊研究员带领的阅读与视觉认知实验室十余年来开展的一系列针对中文阅读中的认知机理进行研究工作的基础上完成的。相关研究先后得到国家自然科学基金面上项目(31970992,31571125,31070904)、自然科学基金委重大国际合作项目(61621136008),以及中国科学院知识创新工程重要方向项目的支持。
论文信息:Li, X., & Pollatsek, A. (2020, July 16). An Integrated Model of Word Processing and Eye-Movement Control During Chinese Reading. Psychological Review. Advance online publication. http://dx.doi.org/10.1037/rev0000248
附件下载: