
心理所建立中文文字概率词汇表与时间间隔表述开放数据库
在做决定时,人们几乎每天都在面对概率和时间信息:事情发生的可能性有多大?结果会在多久之后出现?这些信息关乎人们的风险评估、未来规划以及对复杂事件进程的理解,是个体做出明智决策的重要基础。在现实中,概率和时间信息往往并非以精确的数字呈现,而是更多以“可能”“大概”“等一会”等模糊的文字形式出现。人们如何理解这些模糊的概率与时间表述?
为回答这一问题,中国科学院心理研究所饶俪琳研究组开展了两项研究,分别建立了中文文字概率词汇表和中文时间间隔表述开放数据库。
研究一系统收录了343个常用中文文字概率词汇(如“可能”“不太可能”),并为每个文字概率提供了对应的数字概率、隶属函数和词频数据,建立了中文文字概率词汇表。
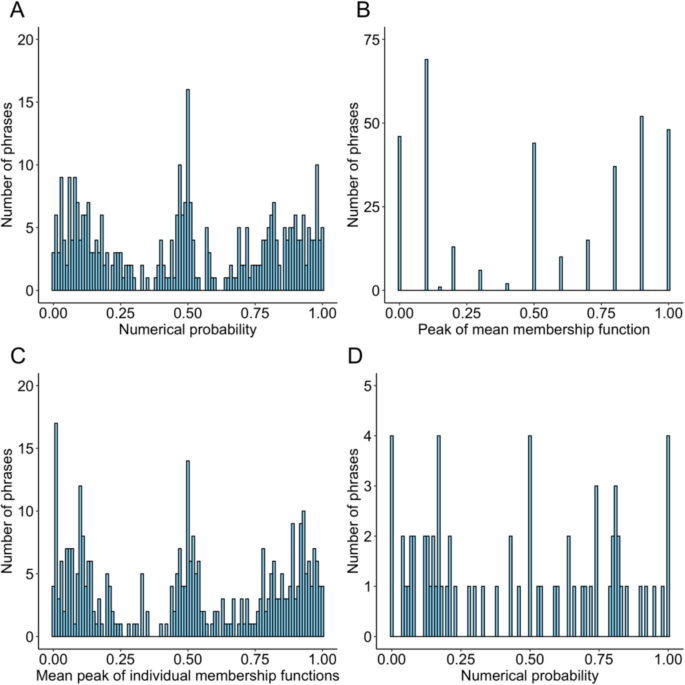
图1. 中文文字概率词语分布
研究团队进一步结合实验测量、大规模语料分析与计算建模,揭示了中文文字概率的数值分布特征,并与英文文字概率进行了跨语言对比,发现中文使用者对小概率事件赋予的主观价值较低(见图2)。
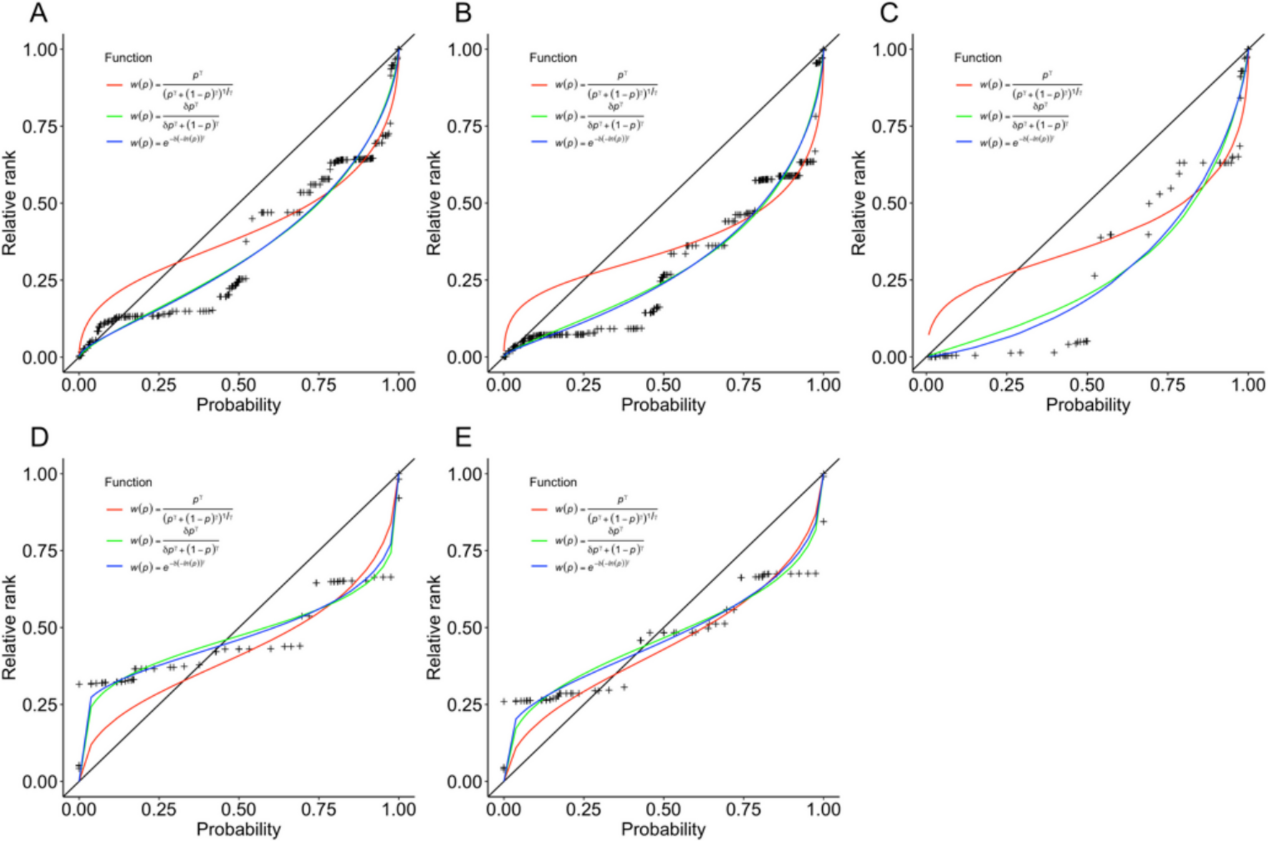
图2. 中英文文字概率主观价值分布与比较
研究进一步提出了七个高频文字概率的标准化基准,可广泛应用于机构风险沟通、概率语言标准化及心理语言学研究。该成果为风险沟通、跨文化概率语言研究、决策科学与文本分析提供了重要工具。
研究二构建了首个中文时间间隔表述开放数据库,涵盖2101个时间间隔表述,包括数字时间间隔词语(如“3天”“两小时”)与文字时间间隔词语(如“很快”“一阵子”)。每个时间间隔表述均配有相应的数字时间长度和词频信息(见图3)。
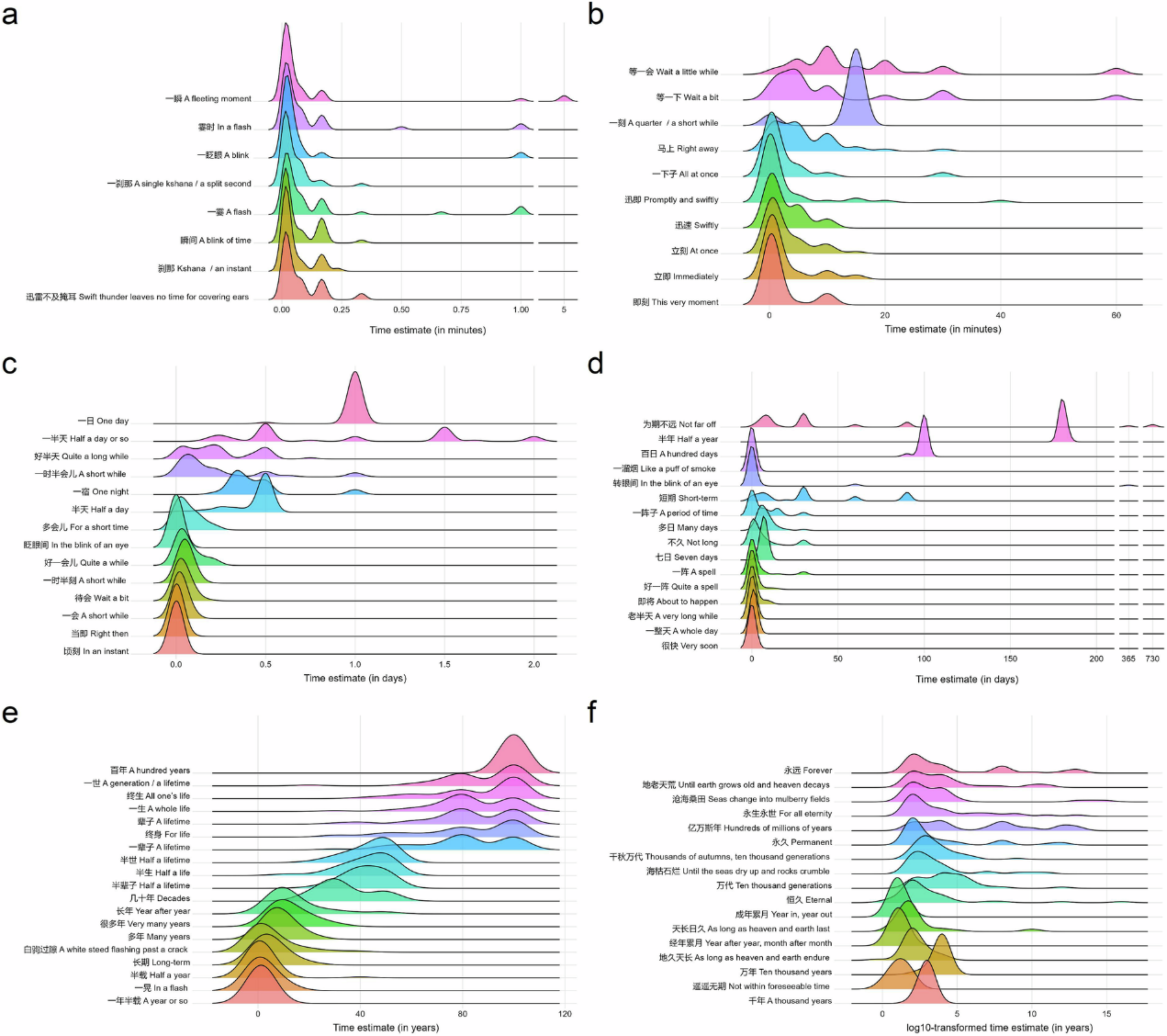
图3. 文字时间间隔表述及其数字表征
该研究首次建立了模糊的时间间隔表述与客观时间长度的对应关系。分析结果显示,该数据库可以准确再现人类时间折扣行为的特征模式,验证了该数据库的质量和有效性(见图4)。该数据库为心理学、语言学和计算科学等领域的研究人员提供了有效的研究工具,为时间信息加工、行为决策建模和自然语言处理等提供了数据基础。
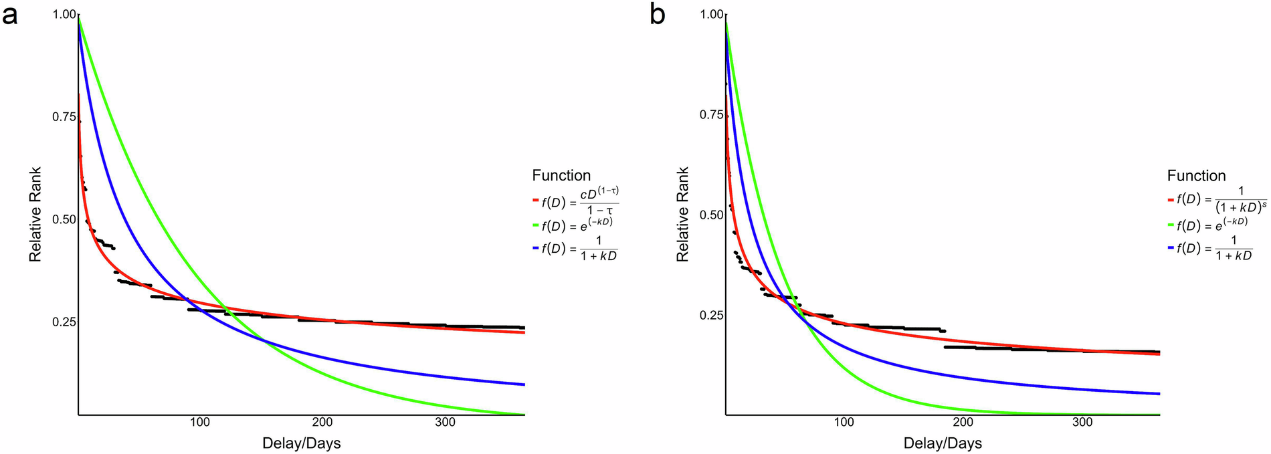
图4. 采用该数据库拟合个体延迟时间的主观价值分布
研究一的成果已发表于Behavior Research Methods,数据库链接https://doi.org/10.57760/sciencedb.19815 。心理所博士研究生隋晓阳(已毕业)为论文第一作者,饶俪琳研究员为通讯作者。该研究受到国家自然科学基金(72371237、92046006、72501312)和北京市社会科学基金青年学术带头人项目(24DTR065)的资助。
研究二的成果已发表于Scientific Data,数据库链接https://doi.org/10.57760/sciencedb.28888 。心理所博士研究生张思琦和硕士研究生牛佳雯(已毕业)为论文共同第一作者,隋晓阳和饶俪琳为共同通讯作者。该研究受到国家自然科学基金(72371237、92046006)和北京市社会科学基金青年学术带头人项目(24DTR065)的资助。
两项数据库已面向全球研究者公开共享,有望在中文语料资源建设、人工智能文本理解及跨文化心理学研究等领域提供参考与启发。
论文信息:
Sui, X.-Y., Niu, J.-W., Liu, X., Rao, L.-L.*(2025). Bridging numerical and verbal probabilities: Construction and application of the Chinese Lexicon of Verbal Probability. Behavior Research Methods, 57, 335. https://doi.org/10.3758/s13428-025-02853-6
Zhang, S.-Q.#, Niu, J.-W.#, Liu, X., Sui, X.-Y.*, Rao, L.-L.*(2025). An open dataset of Chinese duration expressions. Scientific Data, 12, 1732. https://doi.org/10.1038/s41597-025-06016-2
附件下载: