
心理所研究揭示汉语阅读中字形与语音信息的预测加工机制
“我们要保护环境,不能随意砍伐。”当读到这里时,大多数人脑中可能已经浮现出“树木”二字。这种“未见其词、先知其意”的现象并非偶然,而是反映了大脑在语言理解过程中无时无刻不在进行的预测加工。已有研究发现,大脑可以对尚未出现的语义信息进行预测。除了高层语义预测,语言理解中的预测加工能否延伸至更精细词的形式层面?如果可以延伸至词形层面,在阅读理解中大脑到底预测哪方面的词形表征,是字形表征还是语音表征,还是两者皆有?
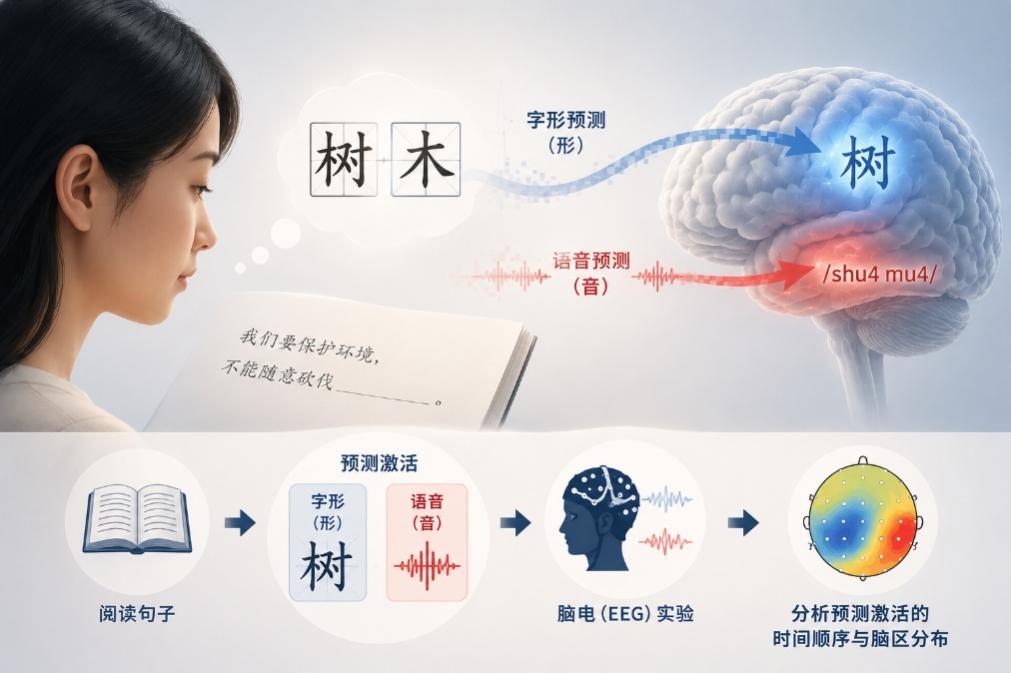
围绕上述问题,中国科学院心理研究所屈青青研究组开展了一项研究。研究利用了汉语字形与语音对应关系的独特属性:汉语中存在大量多音字(如“会”在“会议”中读/hui4/,在“会计”中读/kuai4/)和同音异形词(如“树木”与“数目”读音完全相同但字形毫不相关)。研究者选取在字形上相关、语音和语义无关的词对(会议-会计),以及在语音上相关、字形和语义无关的词对(树木-数目),这种“形音分离”的操纵为解析词形预测的表征本质提供了理想的实验场。
在方法上,研究采用脑电技术,并结合多变量表征相似性分析(Representational Similarity Analysis, RSA)。与传统依赖单一ERP成分波幅的方法不同,该方法把一定时间范围,多个电极通道上的神经活动构成高维时空模式向量,通过计算不同试次之间神经模式的相似性探测预测加工。这种方法通过测量神经表征模式,易于探测目标词出现之前的时间窗口,另外,该方法可以借助SoundShape编码和HowNet语义数据库等模型化的相似性指标,将字形相似性、语音相似性与语义相似性作为独立的维度同时进行量化与控制,更有效地考察词形预测。研究还采用探照灯RSA考察预测效应的分布地图。
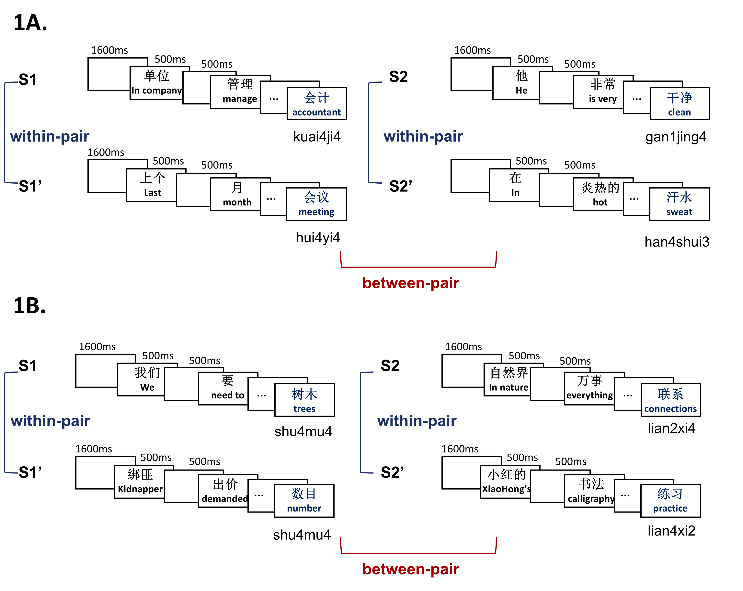
图1.实验1(1A)和实验2(1B)实验设计及实验材料示意图
研究共包含两个实验。实验一聚焦于字形预测。参与者阅读高约束性的中文句子,每两个句子构成一对,两个句子预测字形相关的目标词。例如,一个句子对分别预测“会议”与“会计”:这两个词字形高度相似,但读音完全不同,语义也无关联。如果理解者在句子末尾词语出现之前就预激活了其字形表征,那么预测字形相关词语的句子对,其神经活动模式之间应当比预测无关词语的句子对更为相似。
实验二聚焦于语音预测。句子对分别高度预测出语音相关的目标词。例如,一个句子对分别预测“联系”与“练习”,这两个词的语音相似,但字形不同,语义也互不相关。如果理解者提前激活了即将出现词语的语音表征,预测语音相关词语的句子对也应呈现出更高的神经模式相似性。
结果显示,在目标词出现之前,预测字形相关词语的句子对(实验一)以及预测语音相关词语的句子对(实验二)均诱发了更高的神经表征相似性,为字形与语音表征的预测加工提供了神经证据;目标词出现之后,这种相似性效应依然持续存在,表明在阅读过程中字形与语音表征被持续激活,直到词汇加工结束(图2、图3)。
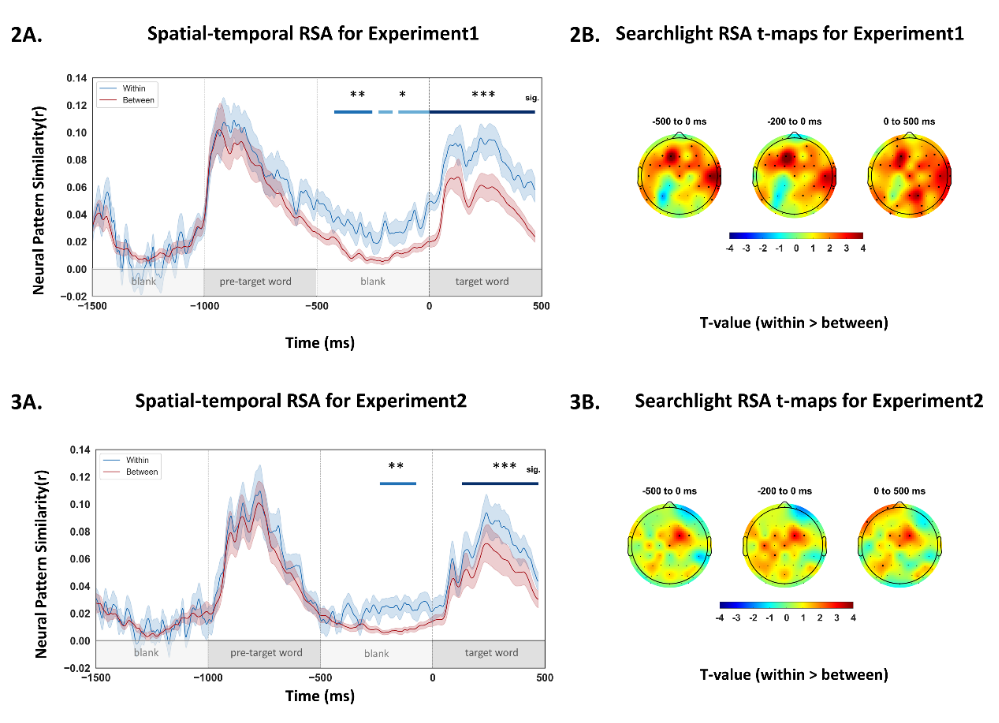
图2-3.实验一(字形预测)和实验二(语音预测)的时空RSA结果及探照灯RSA t值地图
此外,两类预测效应呈现出不同的时间动态:在目标词出现前400毫秒,字形预测效应开始出现;在目标词前200毫秒,语音预测效应才开始出现,即字形预测比语音预测提前约200毫秒;在目标词出现之后,字形激活效应也早于语音激活效应。时间进程的结果提示,自上而下的预测与自下而上的激活,两者的时间动态一致。探照灯RSA的空间分布结果揭示了两类预测在空间分布上的差异:字形预测效应分布范围更广,涵盖额中央区、右侧中央-颞区,并在目标词出现后延伸至顶枕区,这与视觉词形加工区参与字形表征的已有证据一致;语音预测效应的分布更局限,主要集中于额中央区(图2B、图3B)。
研究结果揭示,除了语义预测,阅读理解中的预测加工还可以延伸至更精细的词汇字形表征与语音表征,遵循“字形先于语音”的预测顺序。这些发现深化了我们对语言预测加工与时间动态的理解。
该研究获得国家自然科学基金(32171058)、北京市科技新星计划等的支持。
研究成果已在线发表于Neuroimage。中丹学院博士研究生魏巍为论文第一作者,心理所屈青青研究员为通讯作者,心理所硕士研究生李欣晶为共同作者。
论文信息:Wei, W., Li, X., & Qu, Q. (2026). Pre-activation of orthography and phonology during Chinese reading: Evidence from EEG representational similarity analysis. Neuroimage, 338, 122048. https://doi.org/10.1016/j.neuroimage.2026.122048
附件下载: