
心理所研究发现语音与旋律加工的时频调制敏感性具有跨语言普遍性
在日常交流与艺术欣赏中,人类能够轻松区分“说话”与“唱歌”,其关键线索在于声音在频谱(spectral)和时间(temporal)两个维度上的特征差异。在听觉研究领域,时频域调制(spectrotemporal modulation,STM)已成为分析语音和音乐声学特征的重要工具。已有研究表明,语音与旋律加工存在“不对称性”:旋律感知在频域信息分辨率降低时更容易受损,而语音感知则对时域信息的变化更为敏感(Albouy et al.,2020,Science)。近期研究还发现,STM能够有效区分不同文化背景下的歌曲特征(Albouy et al.,2024,Nature Communications)。然而,既有研究主要围绕非声调语言(如英语、法语)使用者开展,该机制是否适用于声调语言(如汉语)人群,目前尚未得到系统验证。
为探讨这一问题,中国科学院心理研究所杜忆研究组与加拿大麦吉尔大学Robert Zatorre教授、加拿大大学的Philippe Albouy教授,以及法国艾克斯-马赛大学Benjamin Morillon教授合作,共同考察了汉语母语者在语音与旋律加工中对时频调制的敏感性。
研究共设计了两个实验。主实验采用Albouy等人(2020)的实验范式,招募了25名汉语母语者,在时域(1.0、1.5、2.0、2.5、3.5 Hz)或频域(0.6、1.5、1.8、2.0、3 cyc/kHz)分辨率逐步降低的条件下,聆听成对呈现的汉语歌曲片段,并根据提示判断其语音内容或旋律内容是否相同(图1)。对照实验由25名汉语母语者参与,实验流程与主实验一致,但刺激材料为从歌曲中分离出的“无歌词旋律”或“无旋律语音”,以排除多模态刺激可能带来的注意负荷干扰。
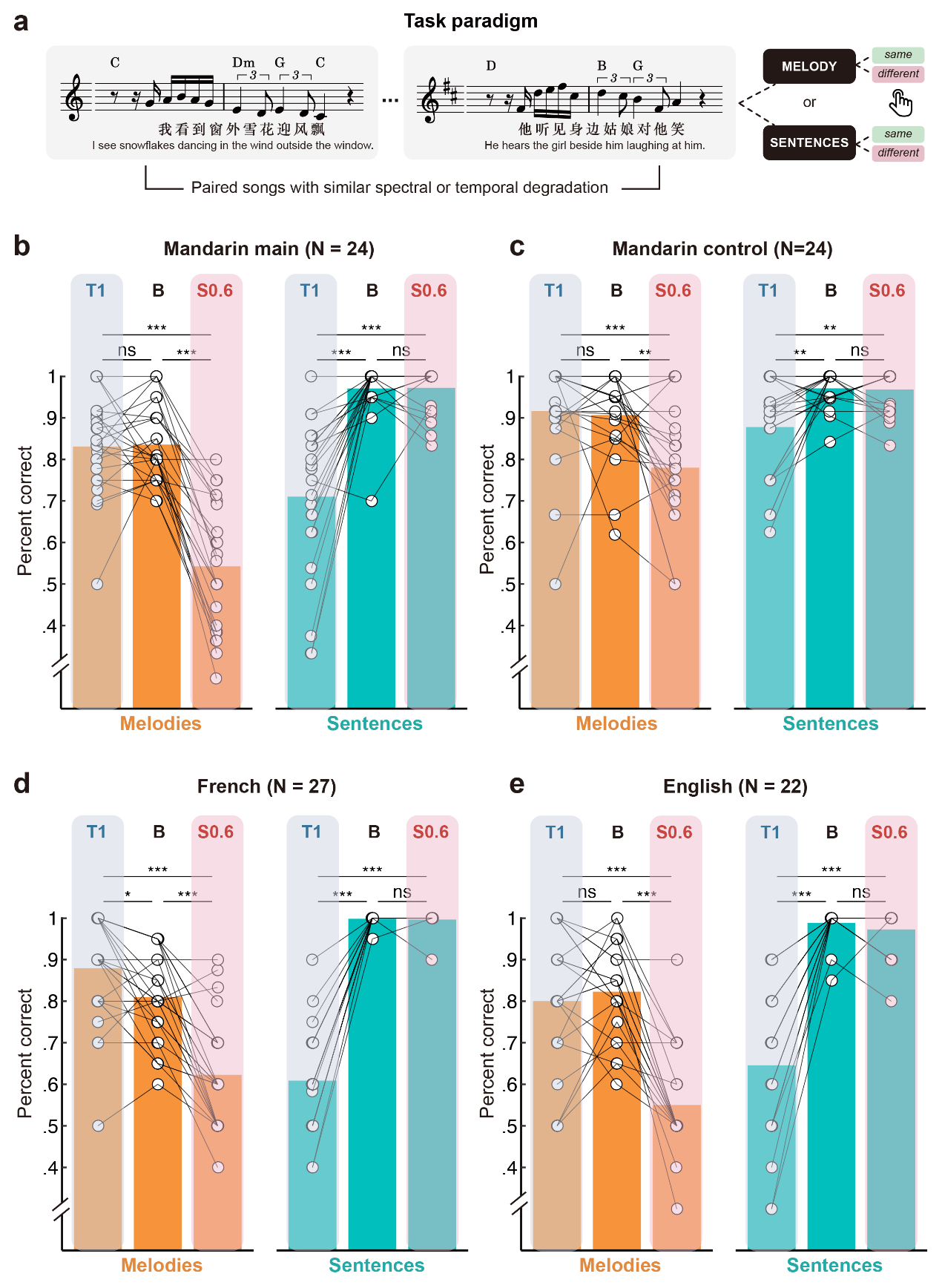
图1. 主实验的实验任务示意
研究结果显示,尽管汉语歌曲在STM能量分布上与英语、法语歌曲存在显著差异(图2),但汉语母语者在行为层面表现出与英语、法语听者高度一致的模式:语音加工更依赖于时域调制线索,而旋律加工则更依赖于频域调制线索(图3)。这表明语音与旋律加工在时频调制维度上的不对称性具有跨语言普遍性。此外,在对照实验中,当旋律或语音单独呈现时,参与者表现趋势一致,但受干扰程度减轻,说明认知负荷在语音与音乐加工中亦起到调节作用。
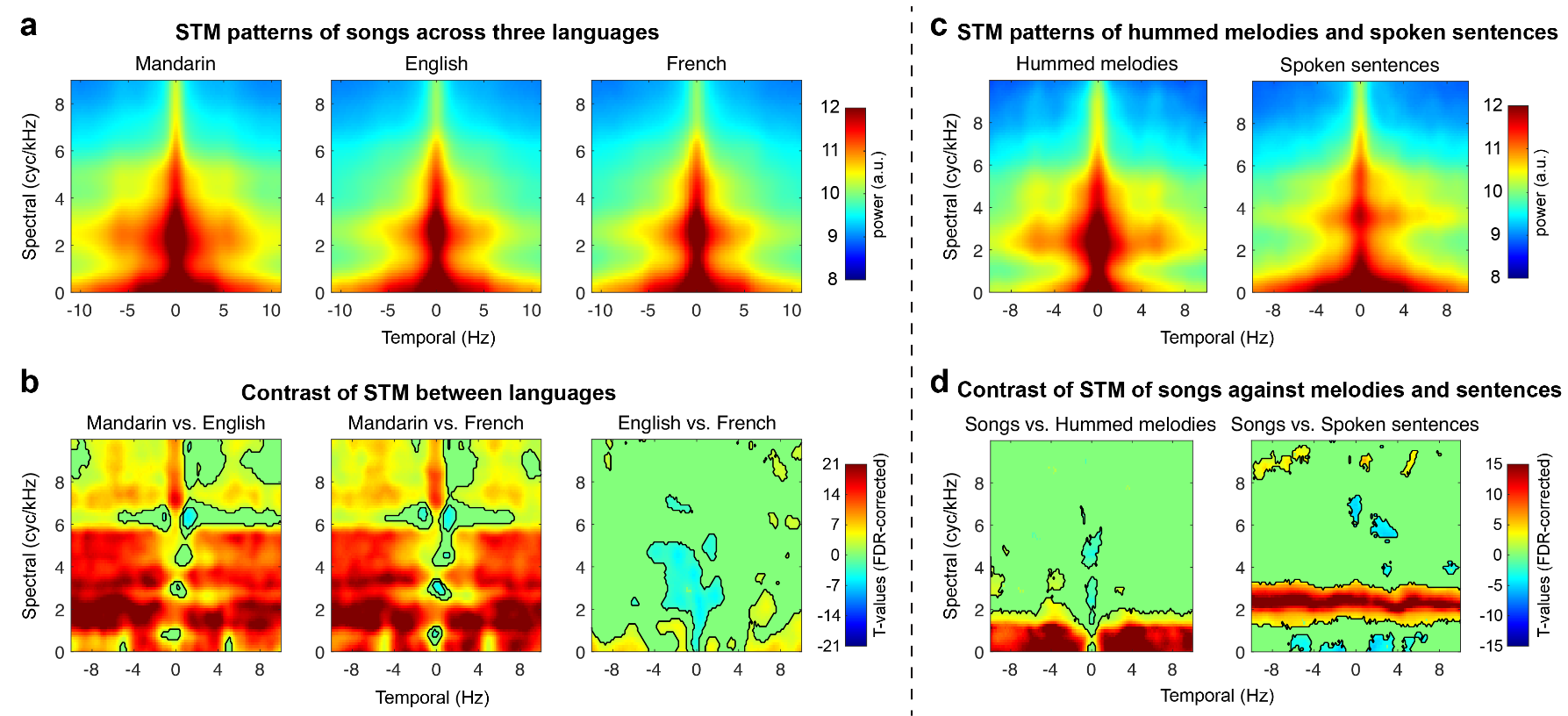
图2. 汉语、法语和英语歌曲的时频域调制能量分布,以及两两语言之间的比较
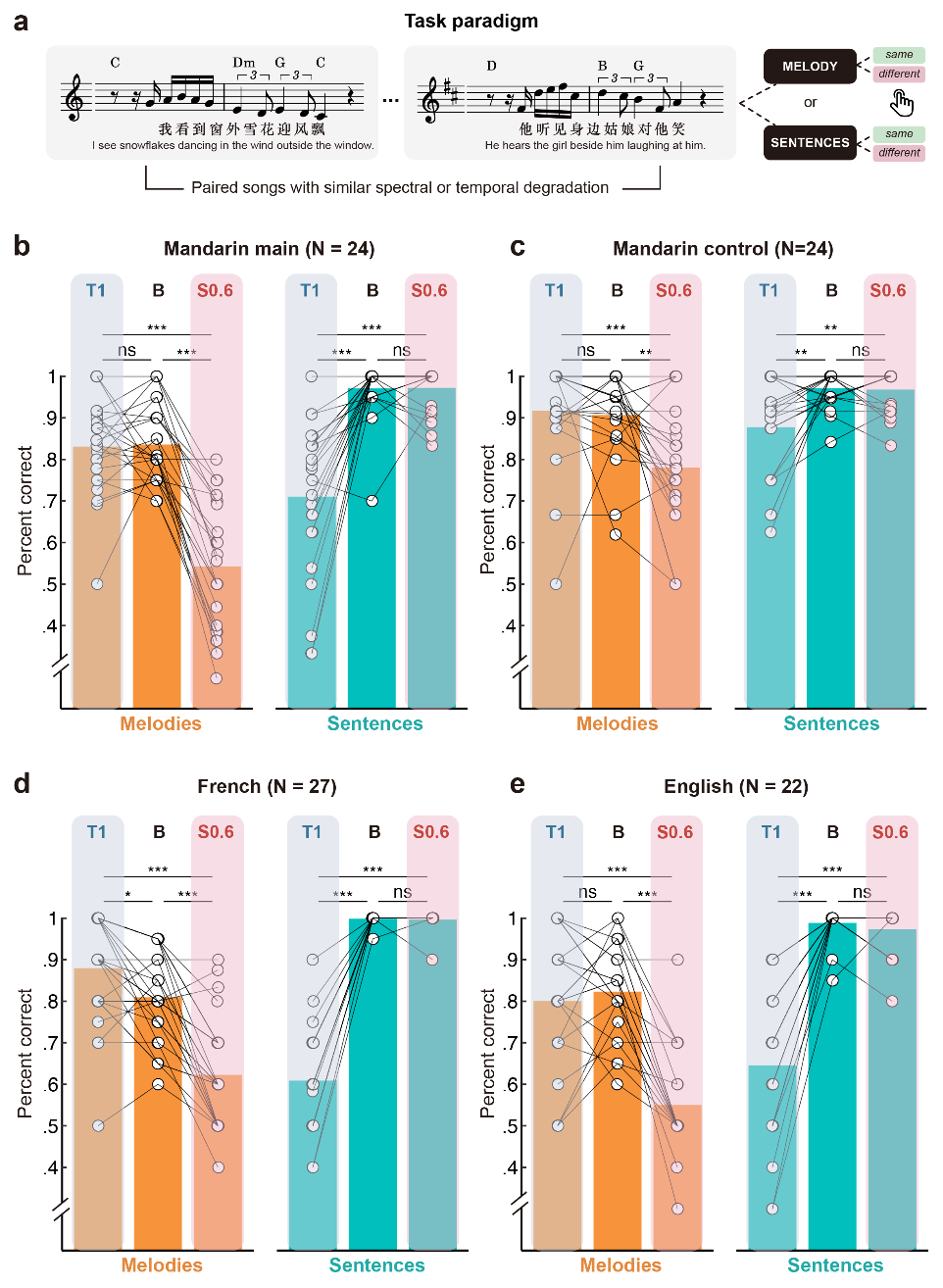
图3. 汉语、法语和英语母语者的旋律和语音感知上的不对称模式一致
值得注意的是,在旋律加工任务中,汉语母语者对频域信息降质表现出更高的敏感性。特别是在约2 cyc/kHz附近的频谱降质条件下,其行为表现呈现非线性变化趋势(图4),这一现象在英语和法语母语者中未见报告。研究者推测,汉语作为声调语言的经验可能增强了使用者在音乐领域的音高加工能力。
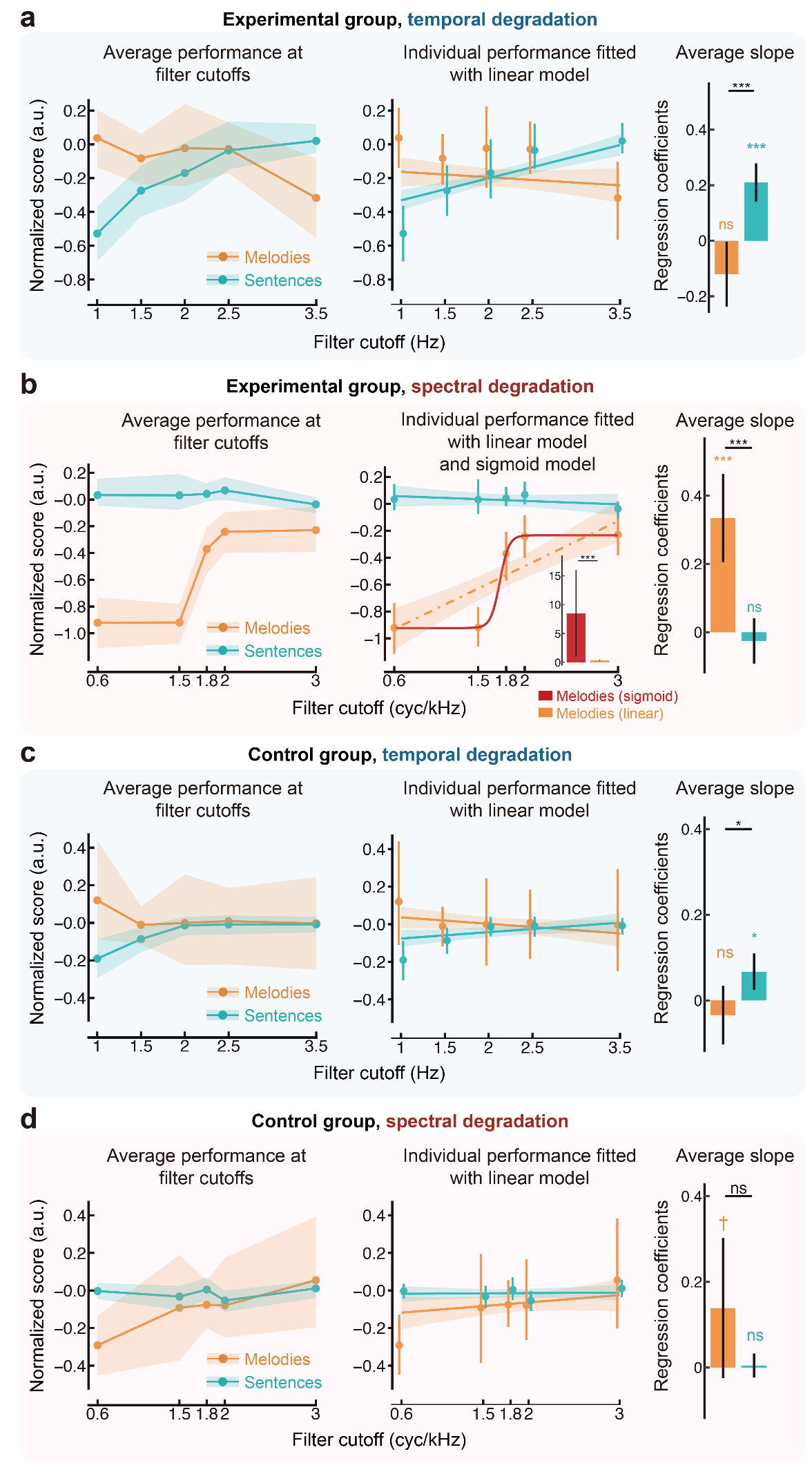
图4. 汉语歌曲中在不同频域调制下的旋律和语音感知表现
综上所述,该研究首次系统揭示了声调语言经验对语音与音乐感知的双重影响:一方面,语音与旋律感知在时频调制线索依赖上的不对称模式具有跨语言普遍性;另一方面,声调语言背景可能在音乐感知中细微地强化了个体对频谱信息的处理能力。该研究发现不仅深化了对语言与音乐感知交互机制的理解,也为进一步探索语言经验如何塑造大脑听觉功能提供了新的研究方向。
该研究获得中国科学院心理研究所科研基金(E4JY292266)、加拿大健康研究院(CIHR)、加拿大研究主席项目(Canada Research Chair program)、法国巴黎听觉基金会(Fondation pour l’Audition,FPA RD-2022-09;FPA RD-2021-6)、欧洲研究理事会(ERC-SPEEDY,ERC-CoG-101043344)、魁北克健康研究基金会(FRQS)、加拿大自然科学与工程研究理事会(NSERC)、加拿大健康研究院(CIHR)及加拿大脑科学基金会(Brain Canada)的资助。
研究成果已发表于Ear and Hearing。心理所博士生吕柏翰为论文第一作者,心理所杜忆研究员和麦吉尔大学Robert Zatorre教授为共同通讯作者。
论文信息:Lyu,B.H.,Li,Y.C.,Albouy,P.,Morillon,B.,Zatorre,R.J.*,& Du,Y.* Spectrotemporal modulation sensitivity in speech and melody processing among mandarin speakers. Ear & Hearing,https://pubmed.ncbi.nlm.nih.gov/41283515/
相关论文:
Albouy,P.,Benjamin,L.,Morillon,B.,& Zatorre,R. J. (2020). Distinct sensitivity to spectrotemporal modulation supports brain asymmetry for speech and melody. Science,367(6481),1043–1047. https://doi.org/10.1126/science.aaz3468
Albouy, P., Mehr, S. A., Hoyer, R. S., Ginzburg, J., Du, Y., & Zatorre, R. J. (2024). Spectro-temporal acoustical markers differentiate speech from song across cultures. Nature Communications, 15(1), 4835. https://doi.org/10.1038/s41467-024-49040-3
附件下载: