
心理所发布首个基于大规模自发言语的汉语学前儿童词汇数据库
词汇数据库是心理语言学和认知神经科学研究的重要基础工具。然而,现有多数汉语词汇数据库主要来源于成人文本、儿童读物或动画等输入性材料,难以真实反映学前儿童在自然交流中“能说什么”以及“如何说”。学前阶段是词汇快速增长的关键时期,但儿童的表达性词汇与理解性词汇在规模和分布上存在显著差异。因此,构建基于儿童真实口语产出的专门数据库,对于深入探究儿童语言发展与认知机制具有重要价值。
近日,中国科学院心理研究所李甦研究组发布了汉语学前儿童口语词汇数据库(Chinese Preschool Children’s Spoken Lexical Database,CPCSLD)。该数据库基于648名北京地区3–6岁儿童在同伴对话情境中的自发言语构建,语料涵盖旅行、玩具、图书、动画、机器人和游乐园等贴近儿童日常生活的主题。整个语料库共包含约120万词次、21372个不同词条、1147个带声调音节和400个不带声调音节,并分别构建了幼儿园小班(K1)、中班(K2)和大班(K3)三个年龄段的子数据库。
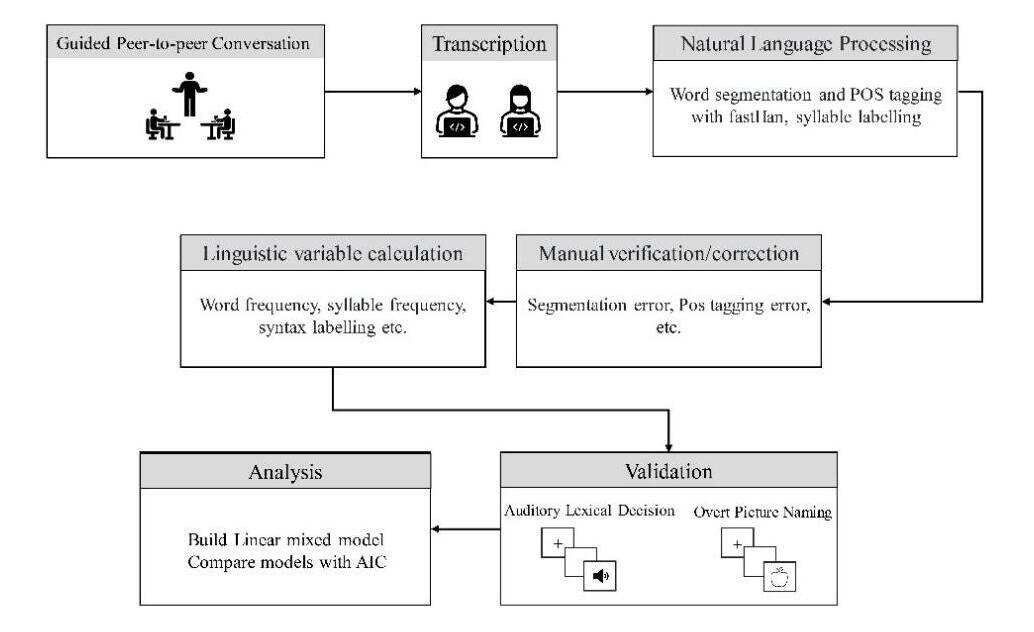
图1. 词汇数据库的构建流程
该数据库系统性地提供了词汇层面和音节层面的多维信息,涵盖词频、词长、词类、音节频率(带声调/不带声调)等多种指标,可用于精细刻画学前儿童口语词汇的结构特征和发展变化。分析结果显示,随着年龄增长,儿童自发言语中多音节词比例逐渐增加,词汇结构日趋复杂;不同词类在表达性语言中的分布也呈现出鲜明的发展特征。
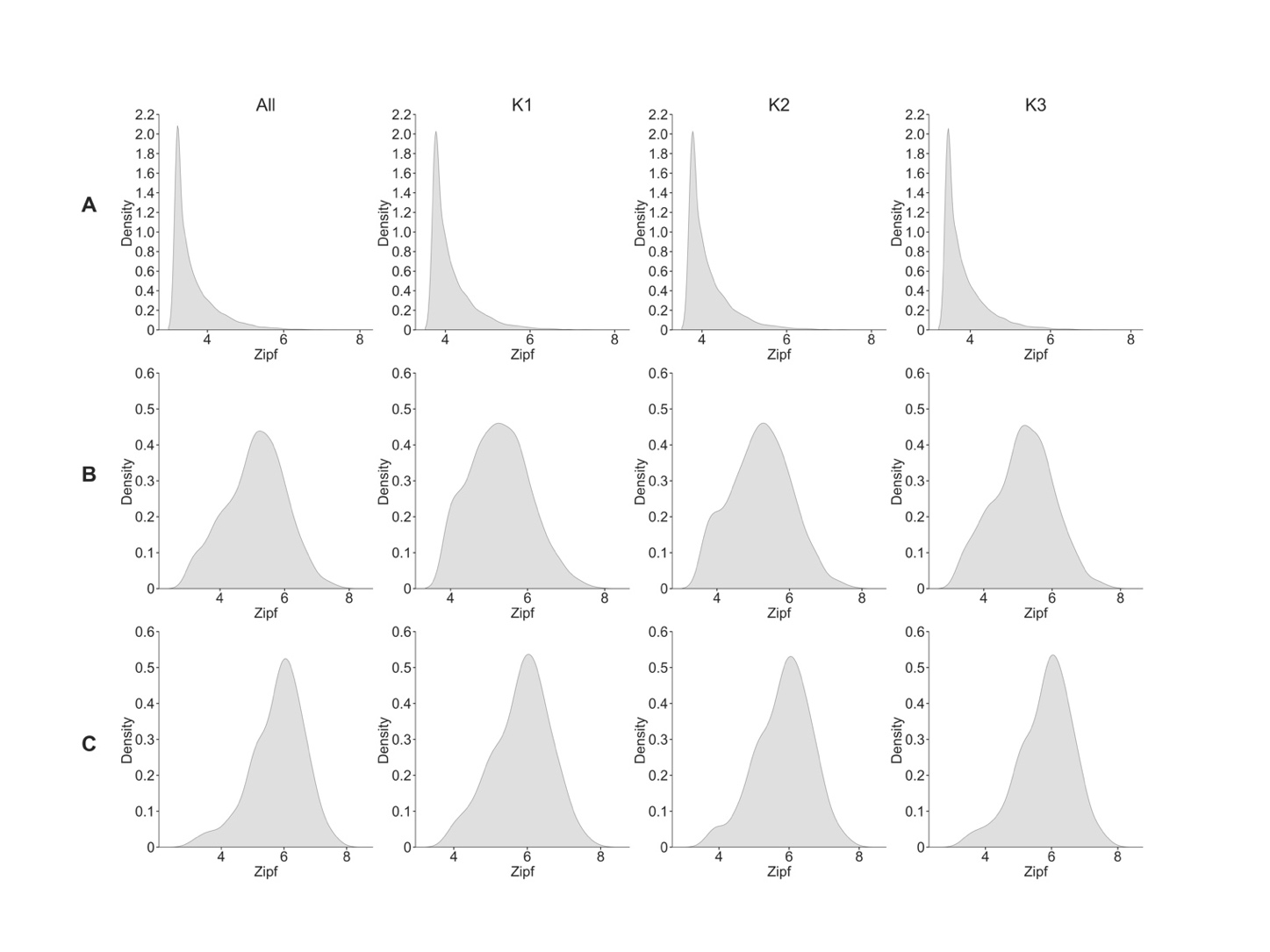
图2. 词频和音节频率的分布
A) 总词汇库的词频分布和各年龄组词频分布;B)带声调音节的总词汇库频率分布和各龄组分布;C)不带声调音节的总词汇库频率分布和各年龄组分布
为检验数据库的心理语言学效度,研究团队进一步将 CPCSLD 与多个已有汉语词汇数据库进行比较,并用于预测学前儿童在语义判断任务和图片命名任务中的表现。结果表明,CPCSLD 在预测图片命名反应时和正确率方面表现出显著优势,优于基于成人语料或输入性儿童语料构建的数据库;而在以词汇理解为主的语义判断任务中,其优势则相对有限。这一结果表明:基于儿童自发言语构建的词汇数据库,更能捕捉学前儿童言语产生过程中的关键统计特征。
该数据库是首个专门面向汉语学前儿童表达性词汇、以自然口语产出为基础的汉语词汇数据库,为儿童语言发展与言语产生研究提供了新的工具。CPCSLD 不仅可用于研究学前儿童词汇和言语产生的发展机制,也可服务于儿童语言评估、语言障碍早期筛查以及教育干预研究。同时,该数据库为探索儿童心理词汇表的组织结构、发展轨迹,及其神经基础提供了重要的数据支撑。
目前,CPCSLD 数据库及相关分析代码已在国家科学数据中心平台公开共享(https://www.scidb.cn/en/s/Vb6vIb),供国内外研究者免费使用。研究团队希望该数据库能够推动学前儿童语言发展研究的深入开展,并为儿童语言教育与干预实践提供科学依据。
该研究得到了国家自然科学基金(31571140)和中国科学院心理所自主部署项目(Y5CX052003)的支持。
研究论文已在线发表于Behavior Research Methods。心理所助理研究员冯臣为论文第一作者,李甦研究员为论文通讯作者。心理所研究助理王嵩为论文共同作者。
论文信息:Feng, C., Wang, S., & Li, S. (2026). CPCSLD: A lexical database of Chinese preschool children’s spoken words. Behavior Research Methods, 58(2), 54. DOI: https://doi.org/10.3758/s13428-025-02931-9
附件下载: