
心理所基于经遗传算法优化的误差反向传递神经网络提出汉语发展性阅读障碍儿童的鉴别模型
发展性阅读障碍(developmental dyslexia,DD)是一种在获得阅读技能方面的特殊困难,影响着5% -17%的学龄儿童,且不能单纯地归因于智力水平、视敏度问题以及学校教育的欠缺。阅读障碍是儿童学习障碍的主要类型,超过70%的学习障碍儿童存在阅读困难。由于致病机理不清,缺乏标准的测试工具,发展性阅读障碍的识别和诊断一直是该领域一个巨大的挑战。
误差反向传递神经网络(back-propagation neural network, BPNN)是人工神经网络(artificial neural network, ANN)的一种类型,具有非线性、自主学习、容错性良好、自我组织以及自适应性等优点,可以通过提供准确的预测来辅助医学诊断。以往研究表明,BPNN模型在医学预测方面优于Logistic回归模型。已有一些研究使用BPNN模型来鉴别阅读障碍或其他学习障碍,表现出良好的预测精度,显示BPNN模型可作为识别阅读障碍儿童的有效工具。然而,这些模型仅应用于拼音文字系统阅读障碍的鉴别。由于汉语和拼音文字在认知加工上存在很大的差异,影响阅读障碍的潜在认知因素也不完全相同,并且不同语言的阅读相关认知技能对阅读障碍的鉴别贡献也有很大的不同,拼音文字阅读障碍的鉴别模型并不能直接应用于汉语阅读障碍的鉴别。
近日,中国科学院行为科学重点实验室毕鸿燕研究组构建了一个经遗传算法优化的BPNN (GA-BPNN)模型,基于近十年来建立的汉语阅读障碍儿童认知行为数据库(人口学数据、阅读相关认知技能成绩)对模型进行训练和验证,开发了针对汉语发展性阅读障碍儿童的鉴别模型。
结果表明,GA-BPNN模型的总体鉴别准确率为94%,并且各项鉴别指标均优于以往的Logistic回归模型。进一步分析还发现,阅读准确性对鉴别汉语发展性阅读障碍的贡献最大,语音意识、拒绝假字正确率、语素意识、阅读流畅性、数字快速命名和拒绝非字反应时对鉴别汉语发展性阅读障碍也具有重要的贡献。其中,语素意识的鉴别贡献排名随年级的增加而上升,但数字快速命名的鉴别贡献排名随年级增加而下降。
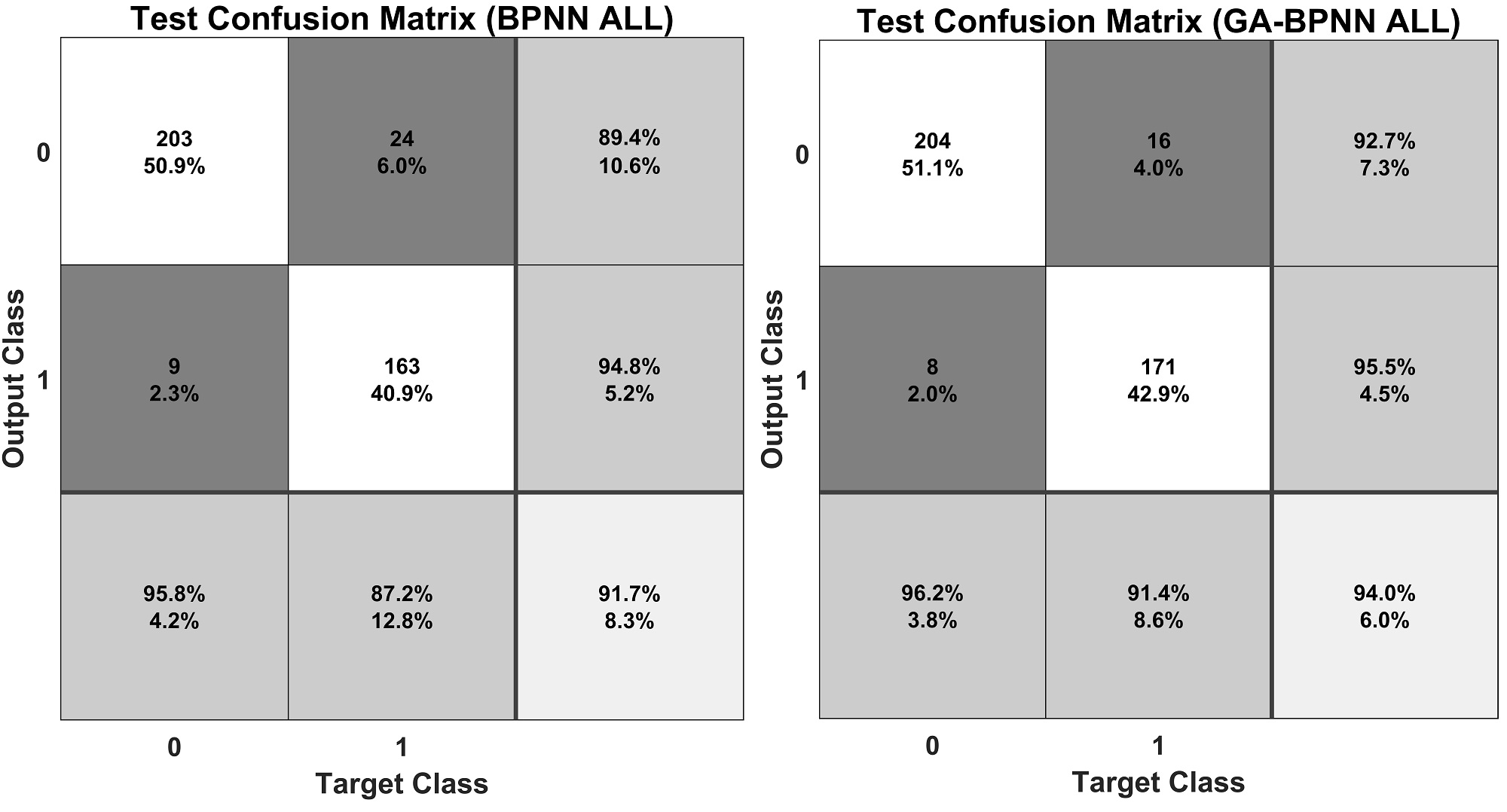
图1 神经网络模型对全体数据鉴别结果的混淆矩阵
注:左图为basic BPNN模型的混淆矩阵,右图为GA-BPNN模型的混淆矩阵
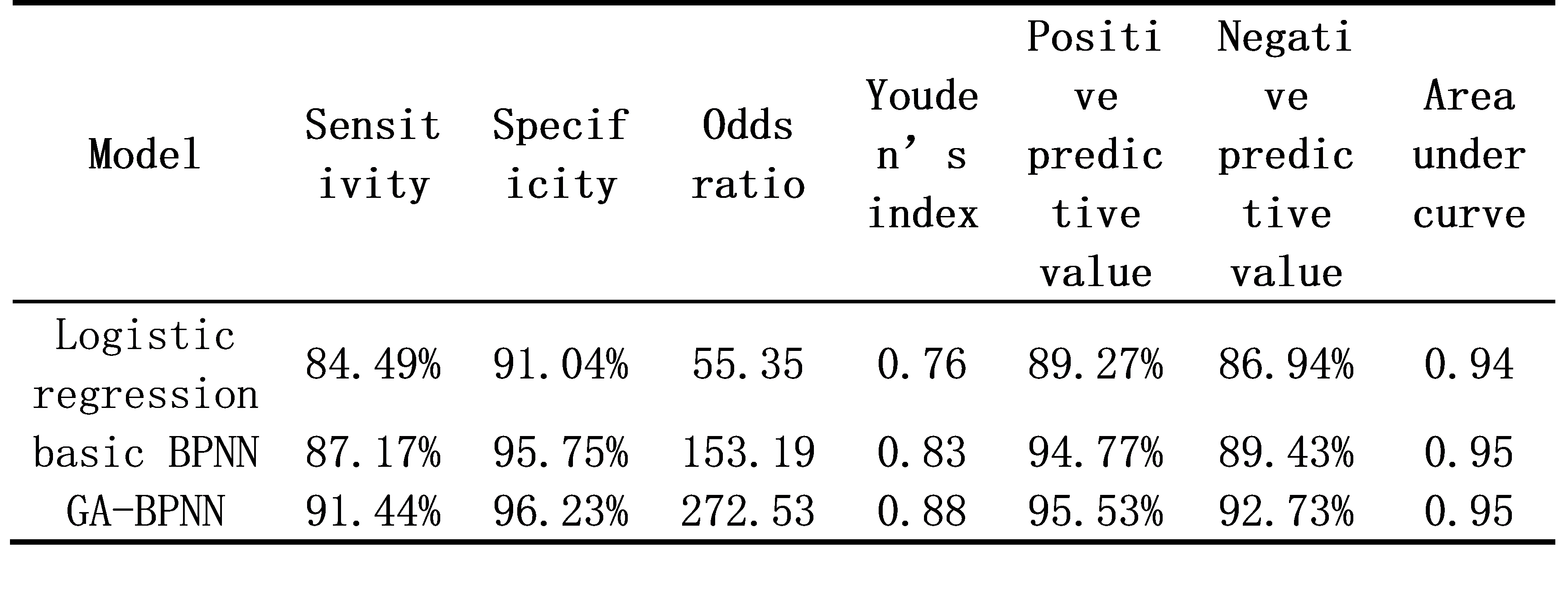
表1 三个模型对全体数据的鉴别评估指标
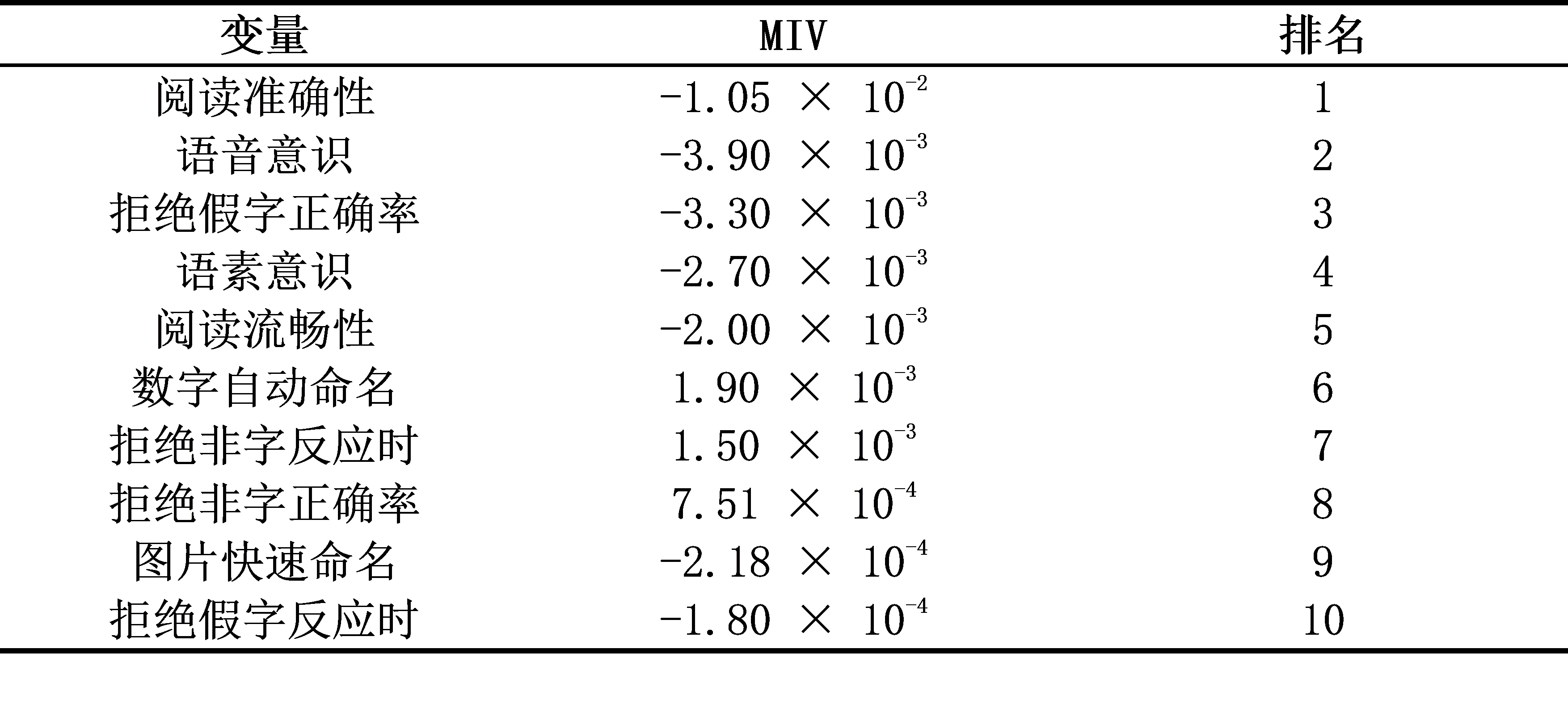
表2 阅读相关认知技能的平均影响值(MIV)及排名

表3 两个年级组阅读相关认知技能的MIV及排名
该研究使用经优化的ANN模型鉴别发展性阅读障碍儿童,构建的GA-BPNN模型对有/无发展性阅读障碍的中国儿童具有良好的鉴别能力。未来该模型的应用可以为汉语发展性阅读障碍提供更有针对性的预防和治疗策略,也为汉语发展性阅读障碍的人工智能专家诊断系统奠定基础。
该研究受到国家自然科学基金项目(31671155)的资助,数据来源于毕鸿燕研究组行为与脑成像数据库,并得到心理所图书馆的数据存储及管理的支持。相关文章已在线发表于计算机科学/人工智能领域学术期刊Expert Systems With Applications。
论文信息:Wang, R. Z., & Bi, H. Y. (2022). A predictive model for Chinese children with developmental dyslexia—Based on a genetic algorithm optimized back-propagation neural network. Expert Systems with Applications, 187, 115949.
https://doi.org/10.1016/j.eswa.2021.115949.
附件下载: